
实习记录(二)
实习记录(二)
此篇文档其实也可叫做小程序性能优化的初步探索,记录我在实习期间对我业务所在领域的小程序进行性能现状数据梳理和部分性能优化实操。
ps:完整的实际性能数据、完整代码不会附上,涉及到隐私信息。
一、数据收集
如何获得小程序启动的各个环节的数据,需要设计一个方法,将各个环节数据上报到监控平台(别用打印这种蠢方式,而且只能针对单个案例,不具有普适性)。
上报的核心使用公司内AegisV2 SDK上报数据。
- 引入相应的wx sdk,进行初始化,组里其实已有相关的上报,不过做的是错误的监控上报;
- 实现测速上报方法reportTime
- 要求传入两个参数:测速名称、测速耗时;
- 进行传入参数的推荐判断,如超过15s不进行上报、耗时的正负等;
- 调用sdk的reportTime方法;
- 实际启动的测速
- 冷启动前的耗时无需我们自定义上报统计,官方的PerformanceEntry里面有一个appLaunch的指标,指的便是冷启动耗时;
- 冷启动耗时的结束点是page的onReady阶段,对应的也相当于是vue的mounted阶段(原因是,两者都是在界面渲染完成后执行,进行DOM操作和相关的初始化任务);
- 在mounted里面设置一个onReadyTime,赋值当前时间(Data.now),接着以此为时间轴,所有时间节点的上报的测速耗时都是一个相对时间relativeReadyTime(Data.now() - onReadyTime);
- 在监控平台根据测速名称拿取时间即可。
二、性能优化
2.1 TTI拆分
一般小程序的数据都可以通过we分析自己获取即可,但是TTI的各环节耗时,需要自己根据代码手动拆分。
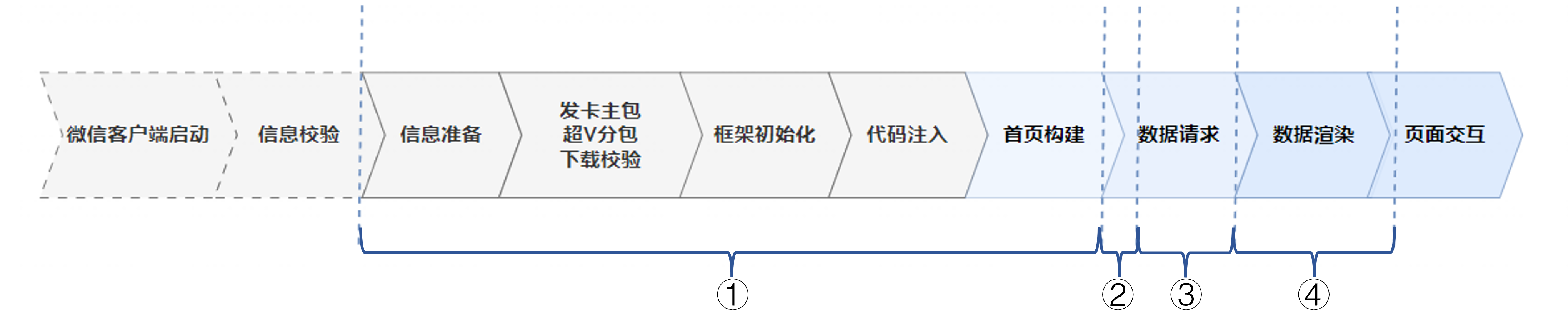
根据整体小程序启动流程的分析,我最终将其分为了四个阶段:冷启动耗时、JS初期的执行耗时、主接口耗时、数据渲染耗时。
但是拿到数据就发现有两点不正常:
- 主接口耗时占比超过TTI的30%,而通过腾讯云API监控发现主接口实际耗时只占测速耗时的2/3,那另外的耗时去哪了?
- 数据渲染耗时偏长,因为我进行了同类小程序的数据对比,在整体TTI优于其他小程序的情况下,此阶段远多于其他小程序,非常不合理!
2.2 接口耗时优化
ps:此项工作是个大工程,请认真观看。
2.2.1 耗时分析
首先我们得知道额外的耗时是如何消耗的,我们才能进行针对性优化。
通过开发者工具performance找出接口请求发起的时间点,发现请求前存在大段无请求的真空时间段。

通过火焰图进行观测,发现由两部分组成:
① 解析和执行JS文件(app.js、页面和组件的js等);② 创建页面和组件实例
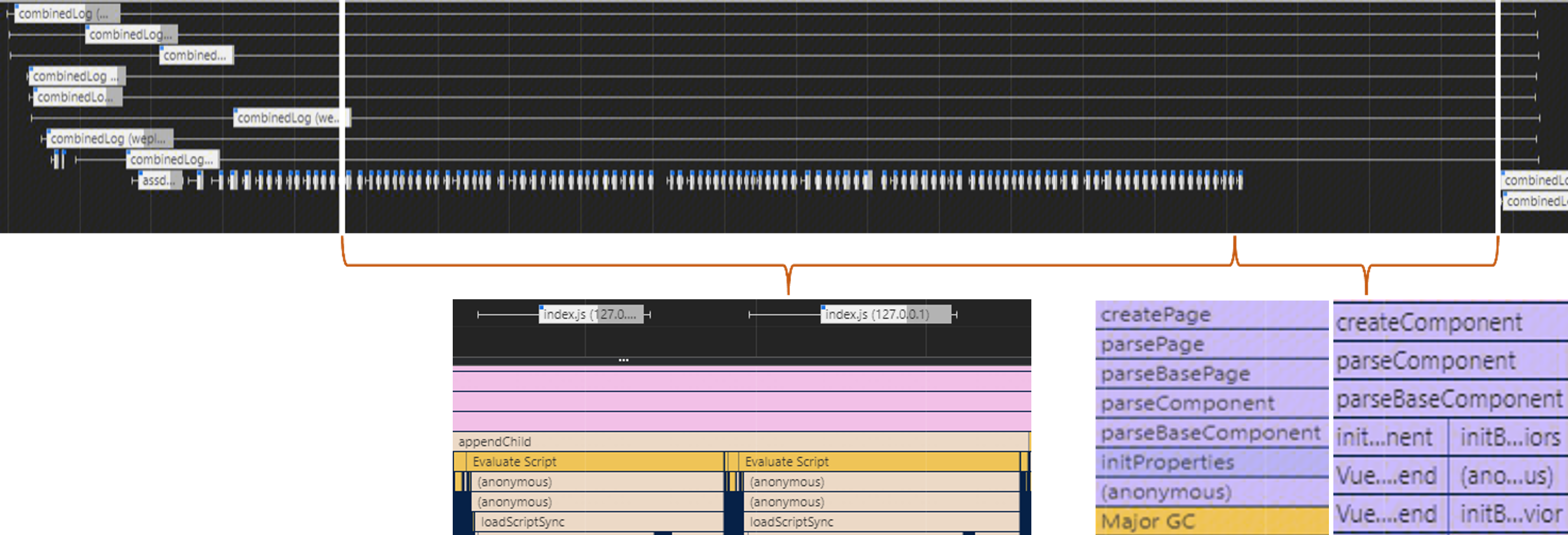
看起来,好像可以把接口请求的时间挪到此提前发起请求,缩短耗时。但还是没找到额外耗时产生的原因。
通过nextwork观测,接口耗时为AB这段时间,通过具体接口的分析,发现其分为三个阶段:
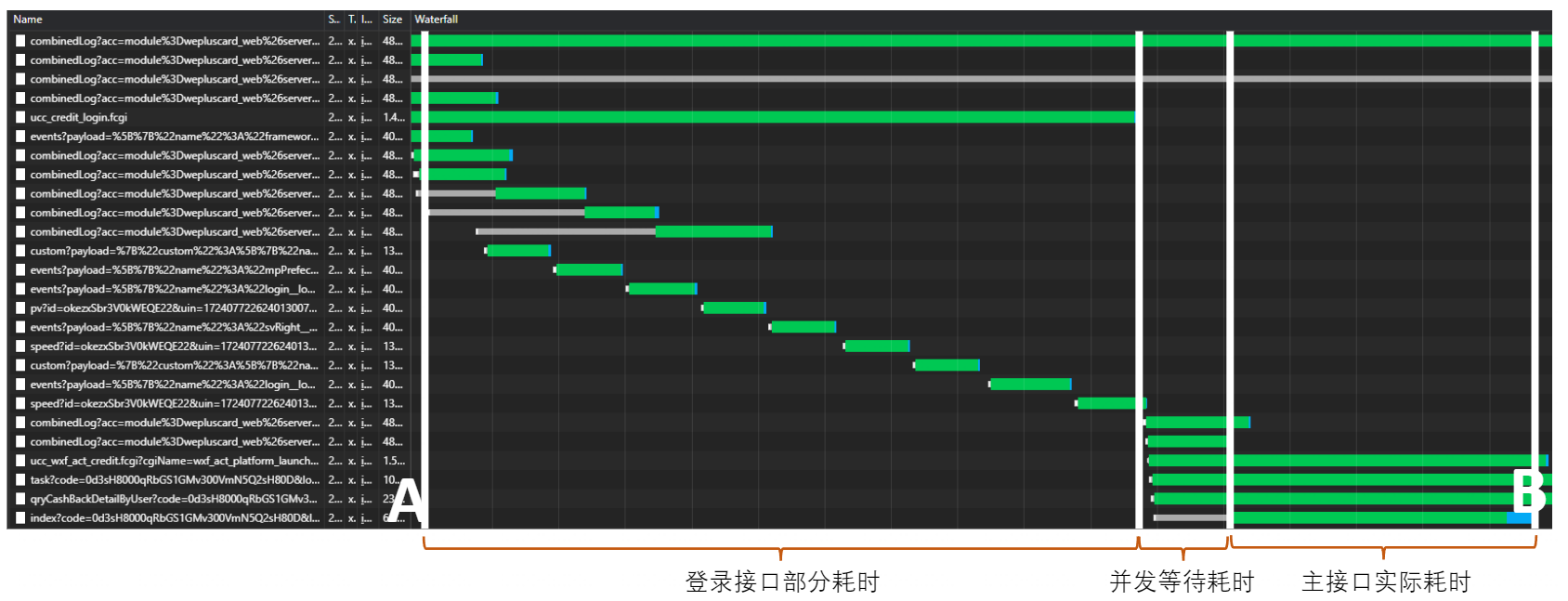
由上可以观测出:接口耗时 = 登录部分耗时 + 并发等待耗时 + 接口实际耗时。
2.2.2 接口提前请求
根据分析,可以自然而然地想到一个优化办法,我把接口提前在真空段发起就行了。
确实可以,但是在代码对应小程序什么生命周期呢?是把登录请求提前发起,那并发等待耗时如何舍去呢?
解决方案:onLaunch是小程序启动是最早触发的生命周期方法,而任何请求都需要登录校验。那在onLaunch阶段发起主接口的提前请求是最有效的方案。
一方面提前将请求整体提前,缩短耗时;另一方面,登录后直接发起主接口请求,剔除并发等待耗时。
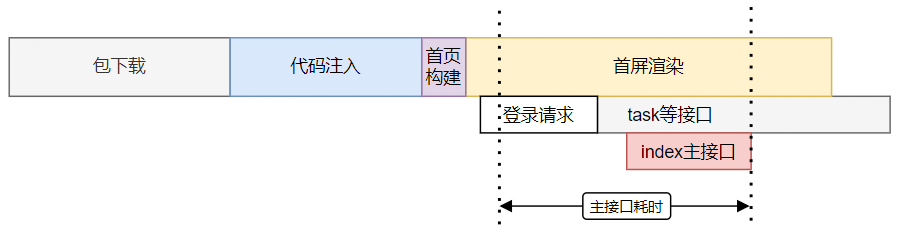
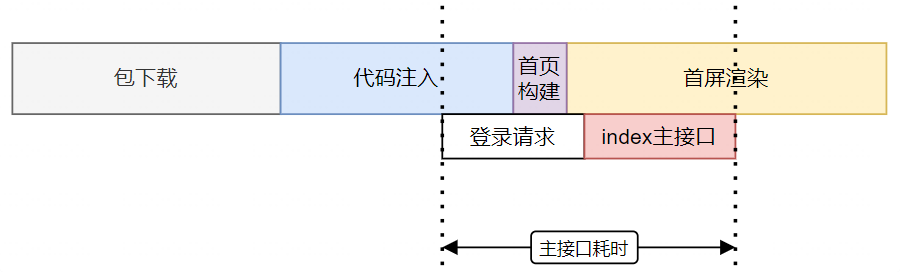
最终通过实际测算,对主接口耗时提速9.75%。
2.2.3 数据预拉取
那有没有一种方式去更早的发起请求缓存数据的方式呢?
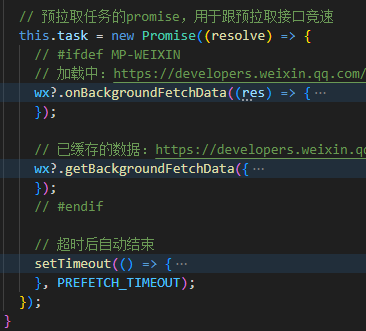
通过研读开发者文档,发现存在一种方法:数据预拉取。
数据预拉取:在小程序冷启动时,通过微信后台提前向第三方服务器拉取业务数据。微信后台指的是微信客户端的后台处理机制。
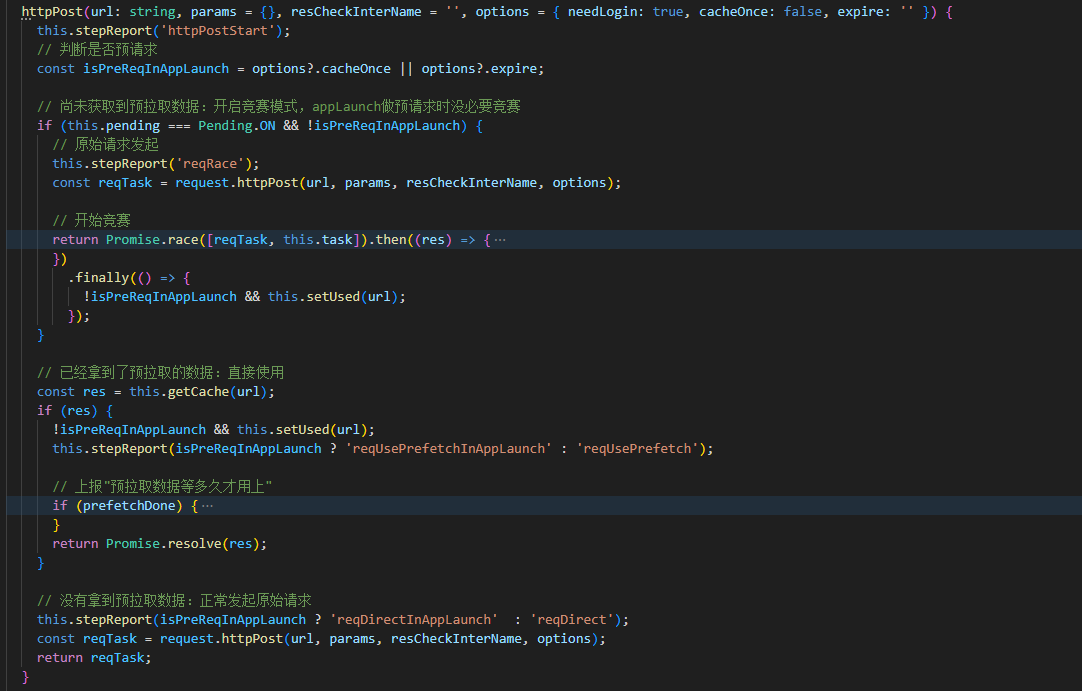
配置预拉取接口
在小程序MP管理后台配置预拉取的请求接口A(我们这里自然是主接口),其支持HTTPS和云开发。
数据预拉取
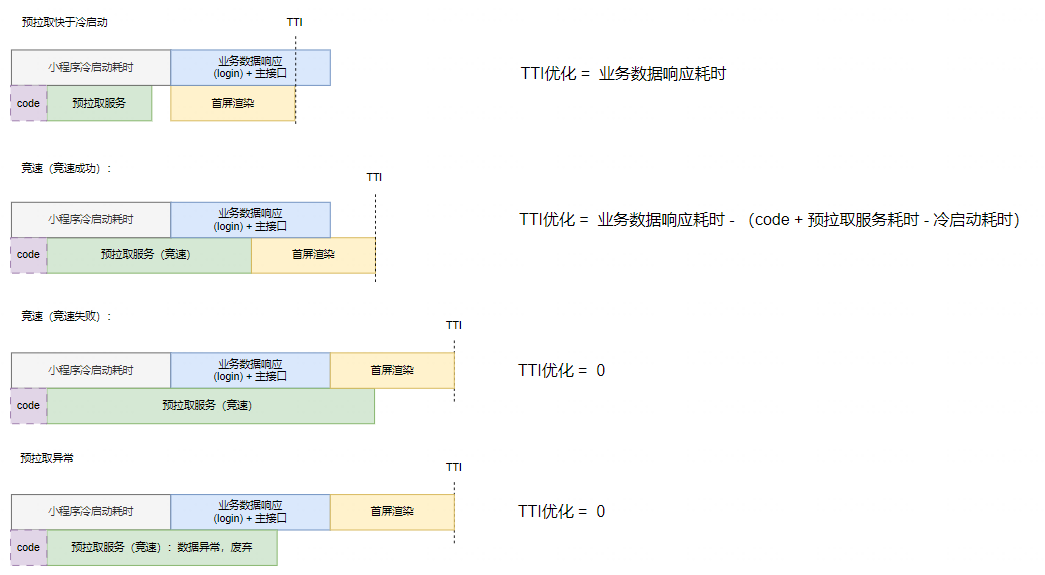
对所需的用卡首页配置对应的接口A,微信客户端启动后,命中预拉取需要先判断有无拉取的token,无则生成code,接着开始数据预拉取:
预拉取结果快于主接口B发起请求的时间点,直接使用预拉取数据
这里存在两类情况:
① 若预拉取结果快于代码包JS注入,则等待注入完毕后,直接使用wx.getBackgroundFetchData获取数据;
② 若预拉取结果慢于代码包JS注入,则需要使用wx.onBackgroundFetchData监听预拉取事件;
预拉取结果慢于主接口B发起请求的时间点,两接口竞速
最终通过实际测速,TTI整体优化19%,收益很大。
这是之前的请求耗时流程:
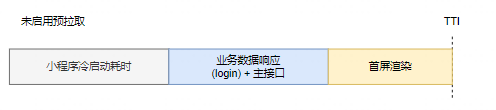
这是使用此方案的耗时流程:
2.2.4 未来优化
其实上述方法还存在优化空间。
仅仅针对当前业务,非整个平台通用方案;
预拉取其实支持任意页面,但本次仅实现首页场景的首页接口,如果新增页面和接口需要开发实现。
token设计
token:用户登录态 & 后台接口入参信息
本次是单一数据结构,写死,不支持多个页面/多接口。
我们要知道各业务接口入参差异较大,业务接口入参 = 默认值参数 + path + 用户信息相关参数 + query。
- token仅携带入参中用户信息相关的可变参数;
- 一个小程序仅有一个token,要做页面与可变参数的映射;
预拉取服务
每新增一个页面,需后台新写页面和接口的映射逻辑实现。
设计:【前端】页面对应的接口,接口对应的接口入参,要完成映射关系。
【服务】解析token,拼接业务接口入参;并发请求,预拉取无需接口串行请求。
2.3 数据渲染耗时
数据渲染耗时本质其实是接口返回数据后setData的过程,不复杂。
通过对页面的数据拆分和代码分析后,发现首页在异步分包后,并没有对数据进行收敛,而是将数据统一放入一个数据结构中,而首页数据获取又存在多个接口,导致数据被不断更新。
根据开发者文档给予的关于setData的建议:

我对此进行了两方面的优化操作:
- 对首屏非主数据进行拆离,完成数据更小维度的收敛,从而控制setData的频率;
- 对非主数据进行异步请求,TTI之前确保data只包含渲染所需的主数据。
如何实现这个TTI之后发起非主数据的请求呢?
可以基于promise实现,在lock的函数中,promise被用来创建阻塞点block,一开始处于pending状态,只有unblock被调用,promise状态发生改变,block之后的操作才可执行。
1 | function lock() { |
那我们在主接口请求后,调用nextTick方法,在里面使用ttiUnblock,同时将非主数据的请求和设置放在tti.then中,即可完成要求。
